Studienarbeit
Auf dieser Seite finden Sie eine kurze Zusammenfassung meiner Studienarbeit. Hierbei nenne ich das zu lösende Problem, mein Lösungsansatz, die Umsetzung und das Ergebnis meiner Arbeit.
Was war das Problem?
Die Verfolgung von Bewegungen kann über ein Kamerasystem und optischen Markern, auch Motion Capturing genannt, realisiert werden. Die Nachteile solcher Systeme sind die hohen Anschaffungskosten, die Vielzahl an benötigten Kameras und der komplexe Aufbau dieser. Die zu klärende Frage ist folglich, ob eine Bewegungsverfolgung ohne Marker und mit einfacheren und kostengünstigeren Mittel umsetzbar ist.
Wie habe ich das Problem gelöst?
Der Lösungsansatz
Die zuvor genannten optischen Marker, die an dem zu verfolgenden Menschen befestigt werden, sind feste Referenzpunkte. Ihre Positionen werden während einer optischen Verfolgung nicht verändert, daher kann das zu lösende Problem als Regressionsproblem angesehen und gelöst werden. Die Lösung ist eine mathematische Funktion, die den Zusammenhang der Referenzpunkte findet. Eine solche Funktion kann durch das Trainieren eines künstlichen neuronalen Netzes gefunden werden.
Die Umsetzung
In dieser Arbeit war es das Ziel markante Stellen, in diesem Fall waren es sechs Stellen, auf dem menschlichen Rücken verfolgen zu können. Diese Stellen sollten leicht zu ertasten sein, da an diesen weiße Marker platziert werden. Diese dienen dem Training eines neuronalen Netzes, in diesem Fall eines Faltungsnetzes (Convolutional Neural Network, CNN) als Kennzeichnung. Genauer gesagt, dienen die x- und y-Koordinaten dieser Marker als Labeldaten. Die Koordinaten der sechs Marker wurden händisch für jede Bildaufnahme (insgesamt über 1000 Bilder) bestimmt. Neben den Labels, die zum späteren Vergleich mit der Vorhersage und damit zur Berechnung des Fehlers notwendig sind, werden Eingangsdaten benötigt. Für diese soll das neuronale Netz die Vorhersagen treffen. Hier werden Tiefenbilder verwendet, damit das neuronale Netz nicht nur die Form und die Kontur des Menschen als Bezugspunkte zur Vorhersage der Koordinaten hat, sondern auch noch die Tiefeninformationen. Während des Trainings werden die Daten vermehrt, indem verschiedene Verfahren, wie z.B. das Drehen und Spiegeln der Bilder, angewendet werden. Im folgenden werden links die markanten Stellen, die zu lernen und später zu vorhersagen sind, und rechts ein Beispiel für ein Eingangsbild gezeigt:
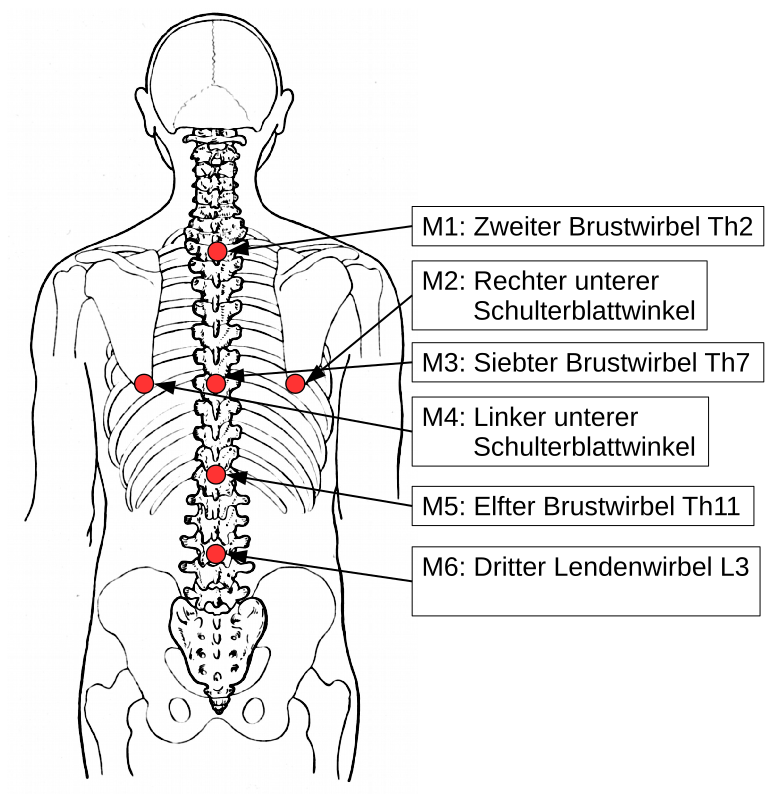

Hier wird das Eingangsbild als Grauwertbild dargstellt, wobei der Verlauf der Graustufen mit der Tiefe korreliert. Je heller die Farbe ist, desto weiter ist dieser Punkt von der Kamera entfernt. Es ist anzumerken, dass der Mensch aus seiner Umgebung über ein Schwellwertverfahren herausgefiltert wurde.
Die Implementierung fand in der objektorientierten Sprache Python statt. Für das Erstellen der Faltungsnetze, das Training, die Validierung und das Testen wurde die Deep-Learning Bibliothek Keras verwendet, hierbei diente Tensorflow als Backend. Für Bildverarbeitungsaufgaben wurden die Bibliotheken OpenCV, SciPy und Skimage verwendet.
Das Ergebnis
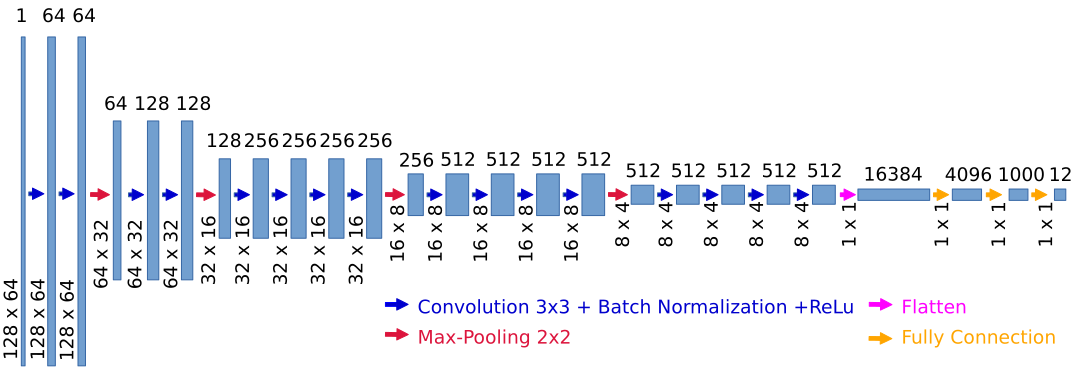
Es wurden eine Vielzahl an CNNs trainiert und getestet. Das beste Ergebnis mit einer Vorhersagegenauigkeit von 97,2% liefert das Modell mit folgender Struktur:
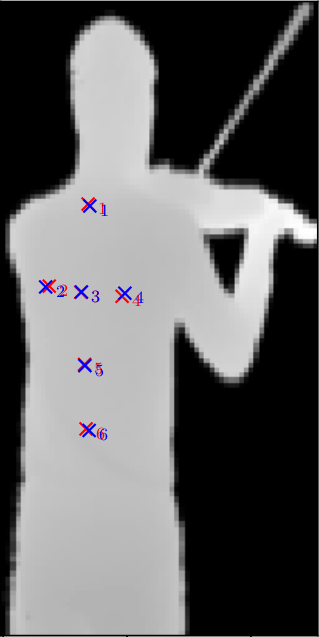
Im folgenden werden drei repräsentative Vorhersagen gezeigt, die das Modell bei unbekannten Daten macht - die blauen Kreuze sind die zu vorhersagenden Positionen und die roten Kreuze sind die Vorhersagen des Faltungsnetzes:


Was habe ich erreicht?
Das Ziel, Referenzpositionen markerlos über ein optisches Verfahren bestimmen zu können, wurde mit einer hohen Genauigkeit erreicht. Hierfür wurde ein Convolutional Neural Network verwendet, das das Regressionsproblem gelöst hat.