Masterarbeit
Auf dieser Seite finden Sie eine kurze Zusammenfassung meiner Masterarbeit. Hierbei nenne ich das zu lösende Problem, mein Lösungsansatz, die Umsetzung und das Ergebnis meiner Arbeit.
Was war das Problem?
Wird ein Bild betrachtet, kann der Mensch sofort Formen erkennen und diese z.B. einem Objekt oder einem Menschen zuordnen. Die Objekt- und Menschenerkennung durch Maschinen nimmt in unserer heutigen Zeit immer mehr an Bedeutung zu, sei es für das autonome Fahren oder in der Industrie 4.0. Der Mensch ist in ständiger Bewegung und in Kontakt mit verschiedensten Gegenständen. Die besondere Herausforderung und auch das Ziel dieses Projektes war es den Menschen in seiner natürlichen Umgebung bei gleichzeitiger Verdeckung durch Objekte in Echtzeit noch genau identifizieren zu können.
Wie habe ich das Problem gelöst?
Der Lösungsansatz
Mein Lösungsansatz war das Trainieren eines künstlichen neuronalen Netzes zur pixelweisen Segmentierung des Menschen. Speziell handelte es sich hierbei um ein Faltungsnetz (Convolutional Neural Network, CNN). Dieses lernt Strukturen, Formen und deren Zusammenhänge. Das Ziel war es jeden Pixel eines Bildes mit hoher Genauigkeit einer bestimmten Klasse zuordnen zu können. Außerdem sollte die Segmentierung in Echtzeit erfolgen. Dadurch wird eine spätere Anwendung im medizinisch-therapeutischen bzw. -diagnostischen Bereich ermöglicht.
Die Umsetzung
Die Segmentierung wurde am Beispiel von Violinisten umgesetzt. Die Geige und der Bogen sind die Objekte, die vom Violinisten gehalten werden und von diesem in der Erkennung zu unterscheiden sind.
Es gibt verschiedene Möglichkeiten ein künstliches neuronales Netz zu trainieren. Ich habe das überwachte Lernen (supervised learning) verwendet. Das bedeutet, dass die Vorhersage des neuronalen Netzes mit dem gewünschten Ergebnis verglichen wird. Die Abweichung wird als Fehlermeldung dem neuronalen Netz zurückgegeben. Dieser passt seine Parameter an und trifft eine weitere Vorhersage. Dadurch "lernt" das Modell genauere Vorhersagen zu treffen und damit den Fehler zu minimieren.
Während meiner Arbeit habe ich unterschiedliche CNNs trainiert und getestet. Das erfolgreichste Faltungsnetz ist wie folgt aufgebaut:
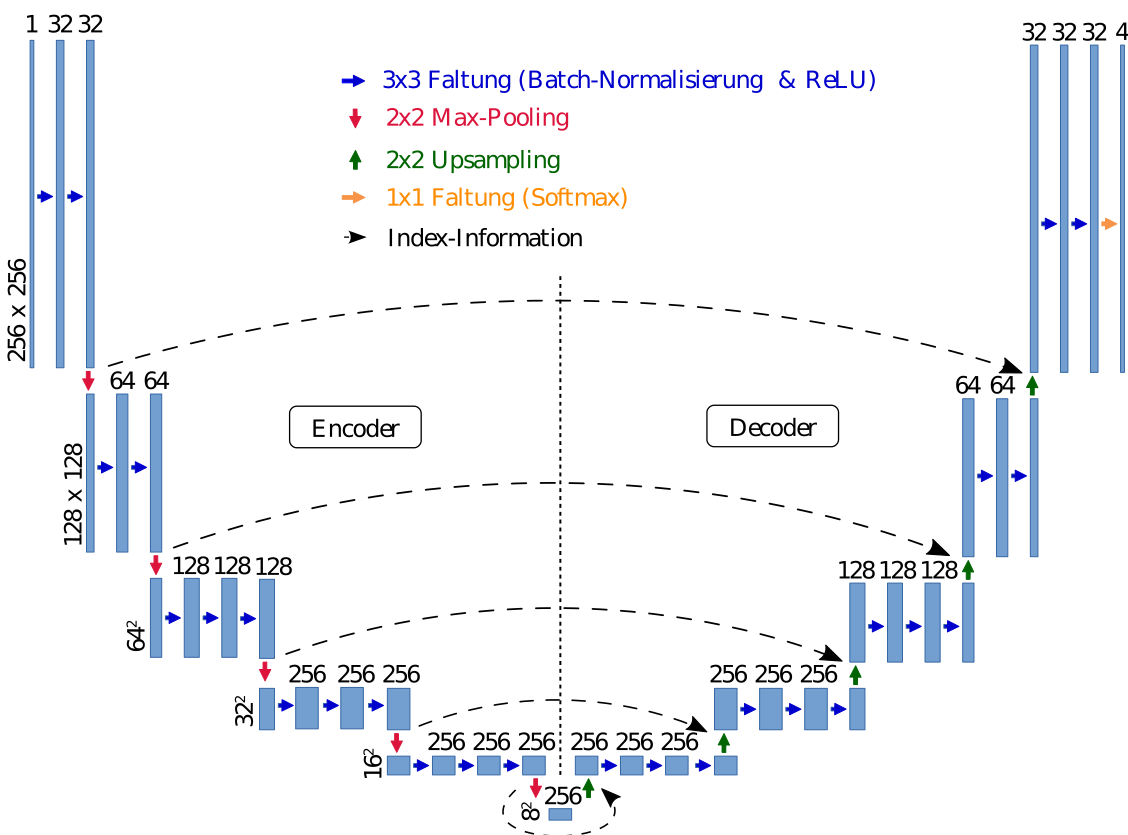
Dem Faltungsnetz dienen Grauwertbilder als Eingang. Das Faltungsnetz hat eine Encoder-Decoder-Struktur, das bedeutet, dass die Auflösung mit zunehmenden Schichten zuerst verkleinert wird und dann wieder auf die ursprüngliche Größe hochskaliert wird. Der Ausgang erzeugt die Vorhersage für vier Klassen, nämlich für den Violinisten, die Geige, den Bogen und den Hintergrund.
Für das Training, die Validierung und die Tests wurden Bilddaten mit der Kinect v2 aufgenommen. Im Training und in der Validierung wurde außerdem ein Datensatz mit Bildern verwendet, die Innenräume zeigen, wie z.B. ein Wohnzimmer oder ein Büro. Ein weiterer verwendeter Datensatz ist der COCO-Datensatz. Speziell werden die darin enthaltenen Bilder von Personen benötigt. Beim Trainieren stellt zum einen die Überanpassung und zum anderen die Unteranpassung ein mögliches Problem dar. Beim ersteren passt sich das neuronale Netz an die Trainingsdaten so gut an, dass es bei neuen Daten keine gute Vorhersage treffen kann. Beim letzteren trifft es weder bei den Trainingsdaten noch bei den neuen Daten eine gute Vorhersage. Um beiden Problemen entgegenzuwirken wurde ein Datengenerator entwickelt, der kontinuierlich neue Daten generiert. Damit soll die Generalisierungsfähigkeit des neuronalen Netzes erhöht werden. Letzendlich wurden zwei verschiedene Arten von Eingangsbilder erzeugt. Von beiden sehen Sie jeweils ein Beispielbild:


Nun werden noch die zugehörigen Label (Mensch, Hintergrund, Violine, Bogen) des ersten Beispielbildes als Binärbilder gezeigt, wobei weiße Pixel für den Wert 1 und schwarze Pixel für den Wert 0 stehen:




Die Implementierung fand in der objektorientierten Sprache Python statt. Für das Erstellen der Faltungsnetze, das Training, die Validierung und das Testen wurde die Deep-Learning Bibliothek Keras verwendet, hierbei diente Tensorflow als Backend. Für Bildverarbeitungsaufgaben wurden die Bibliotheken OpenCV, SciPy und Skimage verwendet.
Das Ergebnis
Es wurde eine Vorhersagegenauigkeit von 98% und eine Vorhersagerate von 28fps erreicht. Im folgenden wird die Vorhersage für ein für das trainierte Faltungsnetz unbekanntes Bild gezeigt:


Jeder Bildpixel wird einer Klasse und jede Klasse einer Farbe zugeordnet. Hierbei entspricht die lilane Farbe der Klasse „Mensch“, die orangene Farbe der Klasse „Geige“, die gelbe Farbe der Klasse „Bogen“ und die graue Farbe der Klasse „Hintergrund“.